联系我们
技术支持:13958168331
网站:http://www.dpsw.cn
DPS咨询QQ号:370281714
DPS用户QQ群:139896778
地址:浙江省杭州市西湖区、浙江大学紫金港校区, 浙江大学农业与生物技术学院C座1049室
常见问题
为什么将DPS软件取名为“dps数据处理系统”?
DPS开发的初衷就不仅限于统计分析,而是包括实验设计,统计分析,数据挖掘,预测决策,系统优化等有关数据处理的工作.因此这样取名 。
如何在SCI文章中引用DPS?
今年(2012年),我们在Wiley-Blackwell 公司出版,中国科学院主办的SCI期刊Insect Science上发表了专门介绍DPS使用的文章,可供 专家、学者将DPS用于科学研究,在国内外学术刊物上发表论文时在参考文献中引用:
Tang Q.Y and Zhang C. X.,(2012) Data Processing System (DPS) software with experimental design, statistical analysis
and data mining developed for use in entomological research, Insect Science, DOI 10.1111/ j.1744-7917.2012.01519.x
下载链接
引用该文献发表SCI文章者,我们将给予奖励:发表3篇SCI文章、并在引文中引用该文献的 ,我们将奖励DPS特别赠送版一套(一台机 器使用的DPS最新版本)。
为什么传统的部分实施的“二次回归通用旋转设计”统计分析计算有问题?
如按目前国内有关试验设计统计专著介绍的方法进行分析,由于计矩阵的二次多项式不是严格正交的,故计算结果不是很“准确”。将 4(1/2)设计,由于设计矩阵的二次多项式的几个互作项,即x1x2和x3x4、x1x3和x2x4、x1x4和x2x3之间线性相关,实际上是存在混杂,这时按目前介绍的统计分析方法计算的结果,就会出现差错,这样接 下来的回归方程的统计检验、拟合值,及其模拟预测值均是错的了。
目前在DPS7.05版提出的解决方法是,对有线性相关的互作项,只保留一项,其他则予以说明(它是和前面哪项有线性相关)。这样可 得到准确的分析结果。图2例子中的准确结果如下,这样的结果和将设计矩阵生成二次多项式后用SAS、SPSS计算的结果完全一致。
有关详细解答,见网页点击跳转。
非参数统计检验中各种大样本近似法的统计量所需样本(N)及处理组数(k)至少应该要多大?

在DPS6.05以上的版本中,对上述这些非参数检验方法提供了确切概率计算和Monte Carlo抽样概率计算的功能,以满足小样本时非参数 检验的需要。
如何根据给出的p值来进行统计推断?
DPS在统计分析之后,多数情况下会给出假设检验中的p-值。简言之,p值就是传统 所说的α水平(显著水平)。
p值可以精确地告诉我们检验结果的显著水平,而不用再重复采用不同的α水平。根据p值进行统计推断常用标准是:
如果0.01≤p<0.05,则结果显著。
如果0.001≤p<0.01,则结果极显著。
如果p<0.001,则结果是很高地显著。
如果p>0.05,则结果被认为没有统计显著性(有时记为NS)。
但是,如果0.05≤p<0.10,则有时注记为有倾向性的统计显著。
一般来说,给出p值后,如果p<0.05,则拒绝H0,即结果有统计学显著性;如果p≥0.05,则接受H0,即结果没有统计学显著性。
如何看待统计学上的显著性?
统计学上的显著性和科学上的显著性是有区别的:一个研究结果统计上显著并不表明此结果在科学上是多么重要,这种情形特别容易发 生在大样本时,因为大样本中一个很小的差异也可以被统计检测出来(如有500个样本,当相关系数只有0.0877,确定系数还不到1%,但统计检验结果是相关性显著)。相反,某些统计上不显著的差异结果 可能在科学上是重要的,它可以促使我们进一步加大样本去发现“表面”差异。
有关DPS6.xx版本?
从2005年初开始,DPS推出了6.xx版本,具体地说,其电子工作表更换升级,开发语言升级,因此是一次较大的升级过程。
meta分析功能为什么不放在菜单里面,而是以工作表的方式向用户提供?
meta分析只涉及一些较简单的数据加减乘除、求和,以及几处需要计算概率p值的地方。这用DPS的工作表和DPS提供的统计函数就可以 实现。因此将这些功能放在工作表里面,用户用起来更直观、更方便。
DPS6.xx以后版本的电子表格与前面的版本有何不同?
DPS从6.0版开始采用了新的电子表格,它支持许多原来不支持的功能,如支持鼠标滑轮上下移动,公式的复制更灵活,并可拖动鼠标进 行数字填充等,可极大地减少用户对有规律的数据输入的工作量。
为什么有时候工作表的单元格数据显示不正常?
有时单元格里数值显示出数据不全,如下图的工作表的第二行数据显示的结果不正常。

其原因是单元格列宽不够,遇到这种情况时,将单元格列宽拉宽就可以正常显示了。
有时输入数据,并用鼠标选中后不能分析,为什么?
多半是输入数据时是中文全角方式,这时输入的字符是黑色的。数值应该在“英文数字”状态下输入,输入在工作表里面的数字应该是 蓝色。
从dps v7.55版开始,如果输入的是中文全角字符,可以在菜单方式下执行"字符串转换为数值"功能,将其转换过来。
多因素方差分析的结果看不明白怎么办(来自一统天下论坛)?
这是一个具有混杂效应的方差分析例子。当有混杂存在时,用SPSS软件进行平方和分解给不出正确的结果,如该例用SPSS分析结果中各 个分量的自由度和整个自由度不等(丢失了3个自由度,用SAS计算,III型平方和分解结果也是这样)。但用版主的DPS统计软件计算出来的结果,和上面的不一样(版主认为DPS的计算结果才是正确的) 。
关于Duncan新复极差多重比较问题?
唐先生: 你好! 我是购买并运用DPS软件的用户。我是做玉米区域试验的,一直很相信DPS的分析数据,但最近一组数据使我对此产生了怀疑。附件中是我省区试其中一个点的数据和DPS分析结果,方差分析没什么问题 ,但多重比较结果却值得怀疑。用其他方法计算的Duncan新复极差测验结果不是这样。不知问题到底出在哪里? 云南省农科院粮作所 陈 陈先生,您好! 我不知道您是用什么软件进行计算的,可以肯定,您发过来的用DPS计算出来的结果是正确的。我对您发过来的数据用国外的SAS进行了验算,结果和DPS的完全相同。您可放心使用。 关于DUNCAN多重比较,国内过去的问题较多,包括我们农业高等院校的经典统计教材《......》(版主在这里略去教材名称)中引用的DUNCAN多重比较临界值表都是错误的,在当前的DPS版本中,其 DUNCAN临界值是计算出来的精确值,和国外的SAS软件的值相同。这一点在我的网站上已有介绍。 唐先生: 你好!我主要是按你提到的那本教材计算的,可能问题就出在这里。非常感谢!
为什么用DPS计算得到的Duncan检验临界值和书上的不一致?
当误差自由度等于10,显著水平等于0.05时,用SAS计算得到的值和目前表格上的值也是不一致,DPS计算结果和SAS的结果相同。经版 主考查,原来是该表经H. L. Harter修正过(Biometrics,16,671~685),而有的统计专著上还未改过来(国外的一些专著上也有这样的问题)。

怎样识别Dunnett双侧检验的新表和旧表?
当误差自由度等于20,显著水平等于0.05时,新、旧表不同处理组数的Dunnett检验临界值。

在Window2000下,有时做出的系统聚类图整个是黑色怎么办?
这与有的显示驱动程序有关,但是,您只要在图上用鼠标双击一下,这时会出现图形保存界面,这时,将当前图形保存为".BMP"格式的 图形文件,就可以在画图程序或Word里打开并看到图形。
数据太多,如有几十万个数据作聚类分析,DPS处理不了怎么办?
DPS企业版用户,你可和唐老师联系,将为你对某个模块作特殊处理,完成你特殊的需求。
分析时,提示数据未编辑、定义,或读数据粗出错?
将待分析数据定义成数据块?
某个单元格里不是有效的数值,如全角方式的数字,数值颜色一般是蓝色。
如何删除dps2000版
如想从你的机器上删除dps2000版,请注意在卸载DPS过程中,当系统出现是否删除共享文件(Remove Shared file)提示时,请选择全部 不删除(No to All)按钮,以确保您整个Windows系统安全。
怎样购买DPS软件?
详情见网页www.dpsw.cn/order.html,联系电话:0571-86945271
怎样登记注册?
当您下载,安装DPS后,进入运行的是尚未注册的DPS数据处理系统,这时得到的结果是有误差的,仅供演示用。如需正常使用,必须缴 纳注册费,进行注册。
注册方法是:在DPS演示状态,用鼠标单击屏幕顶部的“帮助”下的“系统信息及注册”,这时就会出一个注册界面,请记下。
“二次正交旋转组合设计”和“二次通用旋转组合设计”的英文怎么翻译?
这两种实验设计方法在国内用得非常多,国内文献中的英文译法可能有几十种.有些译法老外看到的话可能根本不知道是什么东西.这段 时间我在将DPS统计软件"英文化"时寻找翻译方法,得到如下表, 也许是"标准"答案吧,供大家以后发表文章时采用,译法分别为:
二次正交旋转组合设计: Orthogonal rotatable central composite design
二次通用旋转组合设计: Uniform-precision rotatble central composite design
什么是自由度?
自由度(degree of freedom)是统计上的常用术语,其意义是随机变量能"自由"取值的个数。如有一个有4个数据(n=4)的样本, 其平均 值m等于5,即受到m=5的条件限制, 在自由确定4、2、5三个数据后, 第四个数据只能是9, 否则m≠5。因而这里的自由度υ=n-1=4-1=3。推而广之,任何统计量的自由度υ=n-限制条件的个数。
标准差和标准误(样本均数的标准误)的区别?
标准差和标准误都是描述变异的指标,当样本数量一定时,标准差越大,标准误也越大。但是它们所表达的含义是不同的:
标准差是描述个体观察值变异程度的大小。标准差越小,均数对一组观察值的代表性越好。标准误是描述样本均数变异程度及抽样误差 的大小。标准误越小,用样本均数推断总体的可靠性越大。
在应用中,一般来说:
标准差与均数结合,用于描述观察值的分布范围,如医学参考值范围的估计;
多组数据的F检验,当各组数据的样本量大于250个,一行放不下时,可以采用GLM模型方法进行分析,这样各组数据个数就没有限制了 。(06.11.22)
做两样本t检验,或多样本F检验,数据个数大于250个时怎么办?
两组数据t检验,如各组数据较多,可以将数据竖着,放成2列即可;
多组数据的F检验,当各组数据的样本量大于250个,一行放不下时,可以采用GLM模型方法进行分析,这样各组数据个数就没有限制了 。(06.11.22)
“二次多项式回归分析”、“均匀设计回归分析”的异同、即分别适用于哪些情形?
这两项功能菜单,执行的统计计算相同;区别是:进行“二次多项式回归分析”,要求样本个数(n)和变量个数(p)满足关系:n>1+p (p+3)/2
如不能满足这个必要条件,则不能使用“二次多项式回归分析功能”,这时可使用“均匀设计回归分析”方法进行分析,分析时,可由 用户自己选择哪些二次项和互作项进入回归方程,使之回归方程的参数个数少于实验次数(n)。
如果想由DPS自动筛选因子(或因子组合)建立回归方程,这时用户可执行“多元分析”→“回归分析”里面的“二次多项式逐步回归” 、或“多因子及互作项逐步回归”、或“多因子及平方项逐步回归”分析功能。(06.11.22)
非线性回归模型参数估计,要使得待估计参数值在0-1之间,在DPS系统中该如何处理(2007年1月16日)?

根据上述数据,拟合一个4参数的非线性方程,即令4个参数分别为 c1, c2, c3 和 c4;参数没有限制时的DPS拟合方程如下:
x2=(c1*x1+c2-sqrt((c1*x1+c2)^2-4*c1*c2*c3*x1))/2*c3-c4
但用户要求其中的c1和c3大于0,小于1; c4>0; c2没有限制.如何根据这些条件修改拟合方程,进行参数拟合。
首先,估计参数大于0,可用取绝对值函数,如参数c4,在方程中可写为abs(c4);
对于参数c1和c3估计值要在0-1之间,可用表达式 (1/(abs(c1)+1))和(1/(abs(c3)+1))进行参数估计,估计参数值后,再根据该公式 ,求出该项参数估计值。例如如果求得c1=-3,那么方程该项参数估计值=1/(abs(-3)+1))=1/4=0.25。
上面这个方程式为:
x2=((1/(abs(c1)+1))*x1+c2-sqrt(((1/(abs(c1)+1))*x1+c2)^2-4*(1/(abs(c1)+1))*c2*(1/(abs(c3)+1)) *x1))/2*(1/(abs(c3)+1))-abs(c4)
举一反三:如第一个参数限制在(-1,1)区间:(1-2/(abs(c1)+1))
举一反三:如第三个参数限制在(3,5)区间:(3+2/(abs(c3)+1))
为方便建模,版主新增加了区间限制函数 limit(y)=1/(abs(x)+1),以后在公式中只要写该函数就可以了,如上述拟合方程为:
x2=(limit(c1)*x1+c2-sqrt((limit(c1)*x1+c2)^2-4*limit(c1)*c2*limit(c3)*x1))/2*limit(c3)-abs(c4)
怎样解决dps8.50以前版本从Excel复制数据有时出错的问题(2007.03.30)?
有的DPS用户反映,在WinXP系统下,从Excel复制数据到DPS的电子表格,在DPS电子表格粘贴数据时,有时会出现提示为
Access violation at adress 7c93e58 in module 'ntdll.dll'. read of adress 00000000.的错误。
经检查,这是所用电子表格组件Cell和Win XP不太兼容的缘故(在Cell开发商提供的“超级报表”中也存在该问题)。不是DPS程序所产 生的错误。 该问题,我们已和电子表格开发商取得联系。不过最近我们发现了解决该问题的初步方法:选择数据时,在Excel表格中数据的右边多选择1~2列空的表格,这样复制数据,在DPS里面粘贴时 就不会出现该错误了。
DPS使用时容易出错的地方
在用户界面输入参数时,不是“英文数字”方式,输入的值系统不认识,导致运行过程出错。这是必须注意的。
关于多元分析中动态聚类新算法答读者问
***先生,您好:
多元分析中新动态聚类算法,是本人最近才发现的一种新的高效算法,目前尚没有相关文献可供参考。 该算法经验证、测试,确实有效,其效果也出乎了我的意料:我原来想,比SAS、SPSS里面
的k-means方法好点就差不多了。结果是比SAS、SPSS等里面的k-means方法的效果都要好得多,几乎是解决了动态聚类理论认为不能解决的全局优化问题。
出于DPS软件商业秘密的考虑,我们暂时不会公布其算法,望谅解。
致礼
唐启义, 2007年5月5日,于浙江大学
DPS850版在Vista上的安装
运行DPS9.50以前的安装程序,在询问“一个未能识别的程序要访问您的计算机”时指定“允许”,安装时选择“取消”,出现如图所示的 提示框,询问“这个程序可能安装不正确”,指定“使用推荐的设置重新安装”,再指定文件夹如“D:\dpssoft”进行安装。dps10.0以后版本,在Vista下面可以正常使用了。
单因素随机区组设计方差分析计算结果
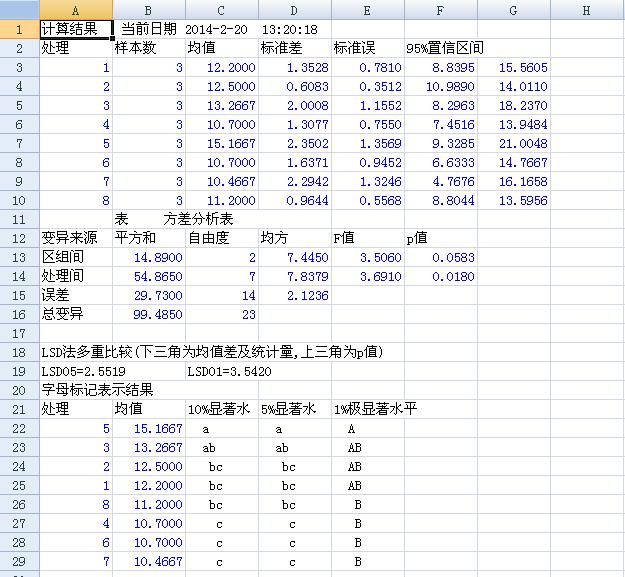
单因素随机区组设计方差分析数据格式
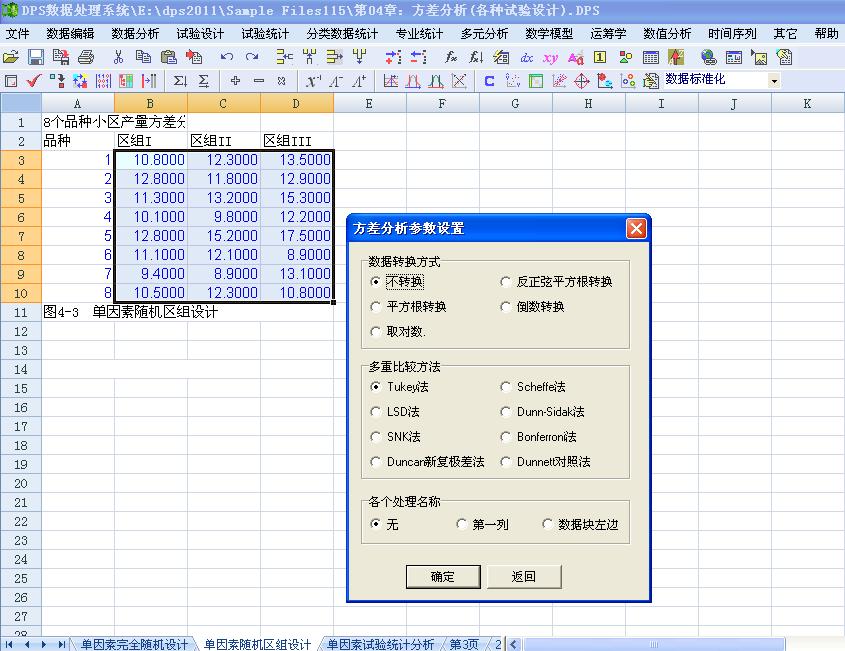
多目标线性规划分析数据格式
方差分析结果解释要点

一次回归正交设计在DPS可以分析吗

另存为功能的使用注意事项
对话框中的星号请改成文件名称
关于对试验结果是否统计分析的对话
用户:请教唐教授一个基本问题:用3种浓度的乙醇提取某种中药,每个浓度重复3次实验,请问3种浓度下获得的提取率要不要进行统计 分析?简言之,什么时候需要对实验结果进行统计分析?什么时候不需要进行统计分析?我以前听一位教统计学的老师说,不涉及到抽样问题,就不需要统计分析。照理说,同一堆中药样品,各部分都 是均一的。你用不同乙醇来提取,不涉及真正重复。可以这么理解吧?如果正确,就不需要统计分析了。所以,看一些发表的文献,有的人可能做统计分析,有的人没做。这次学生论文答辩,对这个问 题就存在争议。
DPS:一堆中药,用某种乙醇提取,重复3一5次,每次结果相同,那就不需要重复,也就不需要统计分析。
用户:“一堆中药,用某种乙醇提取,重复3一5次,每次结果相同,那就不需要重复,也就不需要统计分析”。我的意思是每次提取时 所用的中药完全相同,不存在从总体中抽样,所以对不同浓度乙醇提取时的提取率不需要进行统计分析,只要看哪个浓度的平均提取率高,就可以明确地认为哪个浓度的提取效果好。至于同个浓度每次 提取时的提取率大小不一样,这是试验的系统误差,不是抽样误差。
DPS:不是试验的系统误差,是试验误差。
用户:试验误差包括系统误差和抽样误差吧?
DPS:试验误差包括系统误差和随机误差。系统误差可通过实验设计、和实验条件的控制予以消除。有试验误差的试验,就要设重复,试 验结果就要做统计分析。
用户:任何试验都有试验误差,难道都要做统计分析?误差只能减小,不能避免。统计的最初目的应该是以样本来推测总体,为了消除抽 样误差对试验结果的影响。对吧?
DPS:是的。统计的最初目的应该是以样本来推测总体。通常情况下,总体都是未知的;我们做试验,只是获得样本信息,所以就要进行 统计分析。
用户:还是回到原先的例子,用不同浓度的乙醇来提取中药,比较不同浓度的提取率。这个例子有没有涉及样本和总体问题呢?我感觉 没有涉及。因为一堆中药,充分粉碎混匀后应是均质的,理论上取其中的一部分做试验,可以完全反映全部中药。重复3次的目的是为了减少试验中的系统误差和偶然误差,而不是为了检验抽样误差。再 退一步,如果对此进行统计检验,重复数为3,这个样本量也太小了,对吧。所以,我的观点是这个例子不必要进行统计分析,哪个浓度乙醇的平均提取率高,就说明这个浓度比较合适。不知我的观点是 否正确?
DPS:还是回到原先的例子,用不同浓度的乙醇来提取中药,比较不同浓度的提取率。怎样比较?直观 or 统计检验?或者,回归分析, 建立不同浓度的定量关系。
用户:就是比较不同浓度乙醇的提取率,要不要进行方差分析。如果浓度足够多,进行回归分析倒是可以。
DPS:比较不同浓度乙醇的提取率,需要进行方差分析。
用户:没涉及抽样啊! 再说,每个浓度重复3次试验,重复数也太小了吧。如果每个浓度重复2次,就无法统计分析了。
DPS:那进行分析,总比不分析要好研究分调查研究与试验研究: 调查研究涉及抽样,抽样结果进行统计分析;试验研究,进行试验处理 ,处理结果进行统计分析。
用户:绕了半天,还是没搞清什么时候需要统计分析。比如说,我的体重称了5次,你的也称了5次,比较我们的体重差异,要做统计检 验吗?
DPS:体重反复称重次,是伪重复,Pseudoreplication!
用户:用乙醇提取中药,实质上也是伪重复。因为,每个浓度乙醇重复提取时,所用的中药、步骤都是相同的。这不像你活体动物或植 物,个体间存在不可避免的差异。所以需用统计检验来看看抽样误差的大小。
DPS:试验研究,与是不是活体,没有关系。
用户:再比如,两个人比赛跳远,每人各跳5次。比较两人的成绩差异,也不需要统计分析(T检验)吧。 现在的问题似乎归结到“如何 区别试验的重复是真重复,还是伪重复?”。如果是伪重复,就不必进行统计检验。我好象有点明白了。“两个人比赛跳远,每人各跳5次”。这种情况算不算伪重复?应该不算吧?
DPS:不算
用户:如果每人只跳一次,但用尺子反复测量了5次,这就是伪重复。对吧
DPS:是的,跳一次,5个裁判去量,得到的5个数值,是伪重复
用户:基本明白了。麻烦您的耐心解答。谢谢唐老师。这个问题困扰我很久了。真地很感谢您帮我搞清了。 对于“两个人跳远,每人各 跳5次”这个问题。如果没作统计分析,只根据两人的5次结果的平均值,也可以下“哪个人跳得远”的结论。但不能说,某人的成绩显著好于另一人。是不是?
DPS:是的
用户:只有进行了统计分析,才能比较两人成绩的差异是否达到“显著或极显著水平”,对吧。如果没作统计分析,只根据两人的5次结 果的平均值,也可以下“哪个人跳得远”的结论。但是否也可以诡辩“这种成绩的差异是偶然性的”。所以,对于结果是否真正有差异,还是应以统计检验的结果为准。是这样的吧。 只有经过统计检验 ,其结论才更有说服力。 再回到”用不同浓度乙醇提取中药,比较不同浓度乙醇对中药有效成分的提取率“这个问题。如果每个浓度只重复了2次,其获得的结果就不能进行方差分析,所得结论的说服 力就不是很强。如果重复3次,结果就可以进行方差分析,结论的说服力就强了。如果能重复更多次,结论就更可靠。
DPS:是的。
待续
……